


On November 18, 2025, internet infrastructure firm Cloudflare suffered a major outage that disrupted a significant portion of the web. Beginning around 11:20 UTC (6:20 a.m. ET), Cloudflare’s network experienced failures that caused widespread “HTTP 5xx” error messages to appear on numerous websites. The incident prevented thousands of users from accessing major platforms, including social media (X/Twitter), AI services (ChatGPT), and many others. Given Cloudflare’s role in handling roughly 20% of global web traffic, the outage’s ripple effects were felt worldwide.
Users across the internet encountered Cloudflare’s error page during the outage, indicating an internal failure in Cloudflare’s network (HTTP 5xx errors). This screenshot shows the kind of message seen on sites that became unreachable.
Cloudflare identified that the problem was not caused by any cyberattack or malicious activity, but rather by an internal technical issue. The company’s importance as a “hidden” backbone of the internet became obvious during the disruption – when Cloudflare went down, so did a huge swath of the web. Site owners, end users, and even other infrastructure services were all impacted until Cloudflare fixed the issue and restored normal operations.
Technical Cause of the Incident
Cloudflare’s post-incident analysis revealed a specific software bug in its Bot Management system as the root cause. Earlier that day, a change in database permissions led to a malfunction in how Cloudflare generates a “feature file” – a configuration file that updates firewall and bot-blocking rules. The bug caused the system to output duplicate entries, doubling the file’s size unexpectedly. The network’s servers automatically propagated this oversized feature file across all of Cloudflare’s edge machines.
Unfortunately, the software responsible for routing traffic on those machines had a built-in limit on the size of this config file. When faced with the double-sized file, the router software crashed outright. In essence, Cloudflare’s own update overwhelmed its network’s brain: the processes that direct web traffic couldn’t handle the bloated config data and started failing en masse.
Initially, the on-call teams misinterpreted the symptoms – the intermittent wave of errors looked similar to a hyper-scale DDoS attack, since traffic was failing and recovering in cycles. This happened because the faulty configuration file was being regenerated every five minutes on different database nodes, sometimes producing a good file and sometimes a bad one. This led to fluctuating outages – the network would go down when a bad file propagated, then recover momentarily when a good file replaced it, and then fail again. These oscillations initially made diagnosis difficult. Eventually, as the database update rolled through all nodes, every new file was bad, causing a persistent failure state until engineers intervened.
Timeline of Outage and Recovery
11:20 UTC: Cloudflare’s monitoring detected a sudden spike in errors as the faulty feature file spread, marking the start of the outage. Users around the world immediately began seeing “Internal Server Error” pages when trying to reach sites behind Cloudflare. Within minutes, outage reports on third-party monitoring sites like Downdetector surged to the thousands.
~11:20–13:00 UTC: Cloudflare’s incident response team jumped into action. At first, they suspected an external attack due to the unusual traffic patterns. By analyzing system logs and behavior, they eventually pinpointed the issue in the configuration file. During this period, errors were intermittent (as the network toggled between good and bad config files every few minutes). This was highly unusual, since internal failures typically don’t self-correct temporarily, which added to the confusion.
13:05 UTC: Once the actual cause was understood, Cloudflare initiated a rollback of the offending change. They stopped the generation and distribution of the bad feature file and manually inserted a known-good configuration file into the update queue. Engineers also began restarting core processes (“core proxy” servers) to clear out the bad state.
14:30 UTC: Roughly three hours after the incident began, Cloudflare reported that core network traffic was largely restored to normal levels. In other words, by 2:30 p.m. UTC, most websites using Cloudflare were reachable again for end users. At this time, the company publicly announced that a fix had been implemented and that they were monitoring the recovery.
14:30–17:06 UTC: Cloudflare continued working to recover all services fully. There was a surge of catch-up traffic as previously stalled requests came through, which put extra load on some systems. The team mitigated this by redistributing traffic and gradually restoring all services. By 17:06 UTC, Cloudflare confirmed that all systems were functioning normally and the incident was entirely resolved. In total, the most severe portion of the outage lasted around 3 hours, with some lingering but minor issues for a couple more hours during the stabilization.
Throughout the day, Cloudflare kept customers updated via its status page and social media, for example, just before 7 a.m. ET (12:00 UTC), the company posted that it was aware of a “service degradation” issue impacting multiple services by 8:09 a.m. ET noted that the problem had been identified and that a fix was being implemented. Cloudflare’s London datacenter even temporarily disabled its “WARP” encryption service as a precaution during troubleshooting, as noted in status updates, by 9:34 a.m. ET, the Cloudflare dashboard, and related services were reportedly being restored, and the broader web began to come back online.
Cloudflare Services Affected
The outage’s impact within Cloudflare’s own systems was extensive. Many of the company’s core products and services were either completely down or significantly impaired. Key Cloudflare systems affected included:
-
Core CDN and Security Proxy: Cloudflare’s primary content delivery network (CDN) and DDoS protection services failed, resulting in HTTP 500-series errors being served instead of normal website content. Essentially, Cloudflare’s edge servers could not forward traffic to origin sites, so users saw error pages (like the one pictured above) when visiting any Cloudflare-protected domain.
-
Turnstile (Challenge Pages): Turnstile, Cloudflare’s bot-detection CAPTCHA alternative, was unable to load during the incident. This had a cascading effect: any website or application that relied on Cloudflare’s challenge page for login or verification couldn’t complete those actions. Notably, Cloudflare’s own customer login page uses Turnstile – meaning many admins were locked out of the Cloudflare dashboard because the CAPTCHA widget failed to appear.
-
Workers KV (Key-Value Store): Cloudflare’s distributed database service (Workers KV) experienced a high rate of errors. Requests to the KV store’s API gateway were failing, since the underlying proxy service that routes those API calls was down. This meant applications using Cloudflare Workers and KV storage saw elevated 5xx errors and data unavailability.
-
Cloudflare Access (Zero Trust Authentication): Cloudflare’s Access service, which protects internal applications with login portals, had widespread authentication failures. From the start of the outage until the rollback at 13:05 UTC, most login attempts through Access failed outright. Users with an active session could continue using it, but new logins into protected apps weren’t possible, effectively blocking those applications for many employees and users.
-
Email Security and Other Services: Some of Cloudflare’s email security functions were degraded, too. For a time, they lost access to an IP reputation feed, reducing spam detection accuracy, and some automated email filtering actions failed (though core email delivery was unaffected). Cloudflare’s analytics and monitoring also flagged anomalies due to the incident. However, it’s worth noting that Cloudflare’s data plane – the actual traffic flowing through – was the main thing hit; their control plane (management interfaces) went down but did not directly compromise data passing through Cloudflare’s network.
Cloudflare’s internal teams responded by rate-limiting certain services and scaling up resources as an immediate mitigation. Once the bad configuration was rolled back, each affected service (as above) was restored either through automatic recovery or manual restarts and fixes. The company noted that automatic alerting quickly got the right engineers on the case, and that the failure of a control-plane component (vs. the entire network) helped limit broader damage.
Internet-Wide Impact and Affected Platforms
Because so many websites and applications depend on Cloudflare’s infrastructure, the outage affected a wide range of online services. Users around the globe reported that hundreds of sites were unreachable or throwing errors. Some of the notable platforms and services affected include:
-
Major Websites & Apps: Social media giant X (Twitter) and AI chatbot ChatGPT were among the most prominent services disrupted. Users of both reported errors or issues loading content. Other big platforms like Spotify, Canva, the dating app Grindr, and even Donald Trump’s Truth Social network experienced problems loading. Many streaming and gaming services were hit as well; for example, players of League of Legends and other online games saw connectivity issues early that morning.
-
Financial and Enterprise Services: The outage extended to business and finance sites. For instance, Coinbase (a cryptocurrency exchange) and Shopify (an e-commerce platform) had downtime or degraded performance. Even Moody’s credit ratings site went down, displaying a Cloudflare 500 error page and advising users to check Cloudflare’s status page. Some banking and payment portals that rely on Cloudflare were temporarily unreachable, disrupting transactions.
-
Public Transportation & Government: In the U.S., New Jersey Transit’s digital services were “temporarily unavailable or slow” due to the Cloudflare issue. New York City officials reported that certain municipal services (e.g., emergency management websites) were also affected. Internationally, there were reports of government and local sites facing outages – for example, some observers noted government websites in Denmark had trouble on an election day, likely because their security or DNS was tied to Cloudflare.
-
Developer Tools and APIs: The outage also brought down many developer-focused services. Supabase, a backend-as-a-service platform, and the CDN for Tailwind CSS were reported offline, halting developers’ work. Some continuous integration and deployment pipelines hung up due to unreachable endpoints. Mercury Bank, a fintech platform, saw its dashboard and even card payment APIs fail temporarily. AI model services like Anthropic’s Claude were stuck in loops because Cloudflare’s verification (Turnstile) wasn’t working.
-
Hosting Providers & Smaller Sites: Even relatively minor web hosts and sites felt the pain. For example, Bacloud – a hosting provider, based in Lithuania – relies on Cloudflare, and its customers found their websites showing Cloudflare error messages during the outage (illustrating that this issue hit regional services, not just the tech giants). Many personal blogs and small business sites that use Cloudflare for DNS or DDoS protection also went offline, with no direct way to bypass the issue. In some cases, tech-savvy site owners resorted to emergency measures, such as temporarily disabling Cloudflare’s proxy in their DNS records so that users could connect directly to the origin server. This workaround restored access for some, but at the cost of exposing their server IPs and losing Cloudflare’s security protections.
-
Outage Monitors Themselves: In a bit of irony, Downdetector – the service people use to check for internet outages – was itself partially knocked out, since it runs on Cloudflare’s network. For a while, users couldn’t even verify what was down because “Is it down?” sites (like Downdetector and Down for Everyone or Just Me) failed to load. This underscores how broadly Cloudflare is integrated into online services.
In summary, the incident demonstrated that everything from large social networks to small government portals, from dev tools to transit systems, can be intertwined with Cloudflare. When Cloudflare had a systemic failure, “20% of the internet goes down at the same time,” as one expert put it. The impact was global in scale, with millions of end users affected across virtually every sector of the web.
Cloudflare’s Response and Official Statements
Cloudflare responded to the crisis with swift public communication and internal remediation. As the outage unfolded, the company used its status page and social media channels to keep users updated. Early in the incident, Cloudflare acknowledged the problem, stating it was “aware of and investigating an issue” affecting multiple customers. Shortly afterward, they updated that a spike in unusual traffic had been observed and that they were implementing a fix.
By 14:48 UTC (2:48 p.m. London time), Cloudflare announced: “A fix has been implemented and we believe the incident is now resolved. We are continuing to monitor for errors to ensure all services are back to normal.” This message, posted once core systems recovered, signaled to the world that the worst was over. In the same update, a Cloudflare spokesperson apologized to customers and the internet at large “for letting you down today.” The company stressed that any outage of its network is unacceptable given Cloudflare’s critical role, and it vowed to learn from the incident.
Cloudflare’s co-founder and CEO, Matthew Prince, later that day authored a detailed post-mortem blog outlining exactly what went wrong and how they fixed it. In it, he reiterated that no evidence pointed to an attack or malicious act – it was an internal mistake. Cloudflare took full responsibility, described the fix (reverting the bad file and restarting services), and outlined the plan to prevent a repeat. Notably, Cloudflare engineers had already identified some improvements: for example, ensuring such feature files have stricter size checks, improving testing around database permission changes, and updating their deployment process so a bad update can be rolled back more automatically in the future.
In one statement, Cloudflare said, “We saw a spike in unusual traffic… That caused some traffic passing through Cloudflare’s network to experience errors”. Once they realized the spike was triggering an internal bug, all hands were on deck to restore service. After the resolution, the company admitted the incident was “deeply painful to every member of our team” and that any period where Cloudflare fails to deliver traffic is unacceptable. They also noted that as traffic returned in a rush, they had to mitigate the surge to avoid follow-on issues, but by late afternoon, everything was stable.
Cloudflare’s transparency in the aftermath was generally well-received. They began issuing a formal post-mortem report and communicating with enterprise customers about service credits or SLA considerations. (The outage lasted long enough to breach some uptime guarantees, which could mean refunds for some customers.) The incident also reignited discussions in the tech community about reducing single points of failure on the internet – a conversation Cloudflare itself has often led.
Stock Market Reaction
News of the outage had immediate financial repercussions for Cloudflare. The company’s stock (ticker NET) dropped noticeably once markets opened on Nov 18. In morning trading, Cloudflare shares fell around 2.3% as reports of the disruption spread. As the day went on, the decline grew to roughly 3% by midday, with the stock sliding from the ~$200 level to around $193 per share. This dip wiped out an estimated $1.8 billion in market value within hours. Investors were clearly spooked by the reliability concerns raised – a reminder that even a one-off outage can shake confidence in an infrastructure firm.
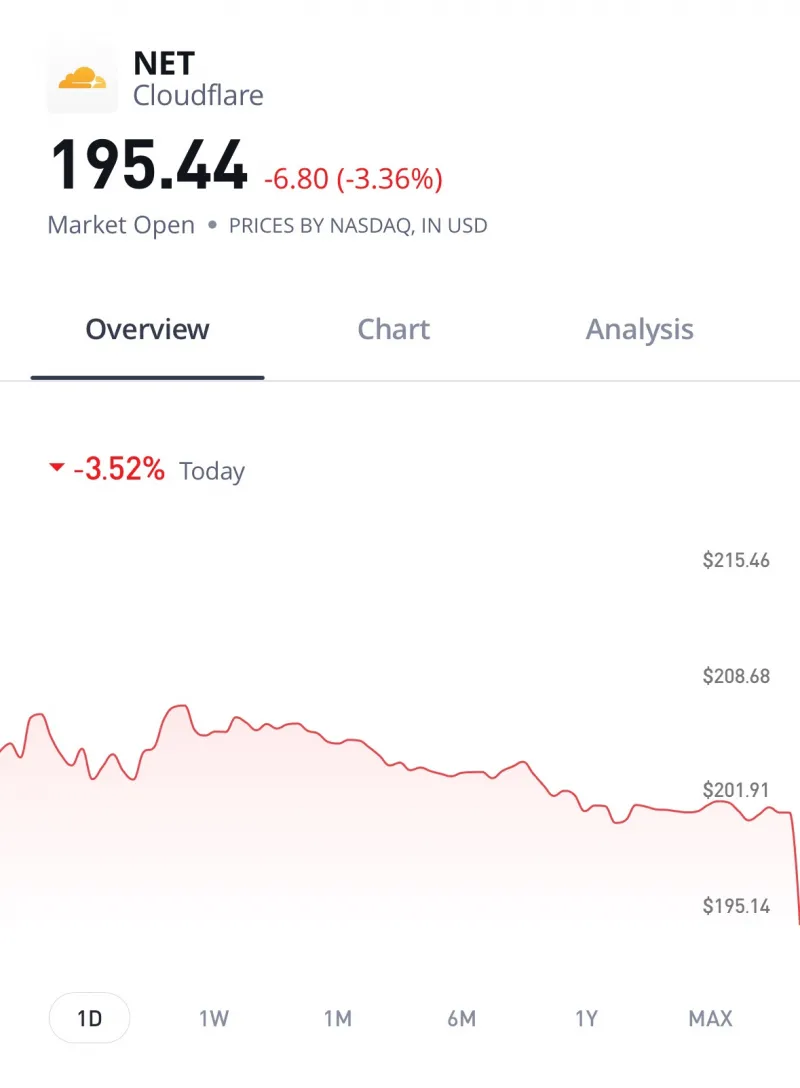
Cloudflare’s stock volatility on that day reflected the market’s broader concern about the fragility of internet infrastructure. When a company that handles a fifth of the web goes down, businesses worry about their dependence on it, and investors worry about potential customer churn or reputational damage. One financial report noted that outages like this highlight the risks of centralized web services – and that companies might start exploring backup providers or multi-cloud strategies to mitigate future incidents. Analysts suggested that Cloudflare will need to reassure clients and investors that it has improved safeguards; otherwise, rivals or multi-provider solutions could gain appeal.
By the end of the day on November 18, as Cloudflare fully resolved the issue, the stock began stabilizing. The quick recovery of services and the company’s proactive communication likely helped prevent a steeper sell-off. However, the incident served as a wake-up call to the market. In subsequent days, Cloudflare’s management faced questions about what changes they would implement to prevent similar failures. The timing was also noteworthy: this outage came just weeks after major outages at AWS and Azure, putting a spotlight on the reliability of cloud and edge networks generally.
Cloudflare’s market cap is heavily tied to its reputation for high availability and trustworthiness. Thus, even a few hours of downtime and a few percentage points of stock dip prompted discussions about resilience. The stock drop, while relatively modest, underscored that uptime is not just a technical matter but a business imperative – any hint of systemic weakness can quickly translate into lost market value.
Conclusion
The November 18, 2025, Cloudflare outage was a stark reminder of how much of the internet relies on a handful of behind-the-scenes companies. A single misconfiguration in an automated system knocked out countless websites, from tech giants to local services, simultaneously. Cloudflare’s post-mortem makes it clear that the cause was an internal error – a latent bug triggered by a routine update – rather than an external attack. In response, Cloudflare moved quickly: deploying a fix, apologizing publicly, and detailing plans to prevent such a scenario from recurring.
The incident’s impact was broad and felt across industries: commuters couldn’t check transit updates, gamers got kicked offline, businesses missed transactions, and even outage-monitoring sites went dark. For a few tense hours, a chunk of the internet’s functionality hung in the balance. That day’s events highlighted both the immense convenience and the potential peril of centralized services. On one hand, companies like Cloudflare enable a faster, safer web for millions of sites; on the other hand, their failure can become a single point of failure for a large portion of the Internet.
In the future, Cloudflare will likely invest in even more robust testing and safeguards (for example, better fail-safes for config updates and more redundancy in its systems). Customers may also weigh the trade-offs of relying so heavily on one provider. The outage sparked conversations about using multi-CDN setups or other backup measures to avoid total shutdowns.
In the end, Cloudflare’s outage on Nov 18, 2025, was resolved within a few hours, and services like Bacloud, X, and ChatGPT returned to service relatively quickly. But the memory of that morning’s internet “blackout” will drive home the lesson that resilience and transparency are critical on today’s web. Cloudflare’s stock dip and swift recovery in the following days indicate that while investors punished the lapse, they will also be watching how Cloudflare learns from it. For the internet community at large, this incident will be cited in future debates on how to build a more fault-tolerant network, given the trust placed in a few infrastructure providers.